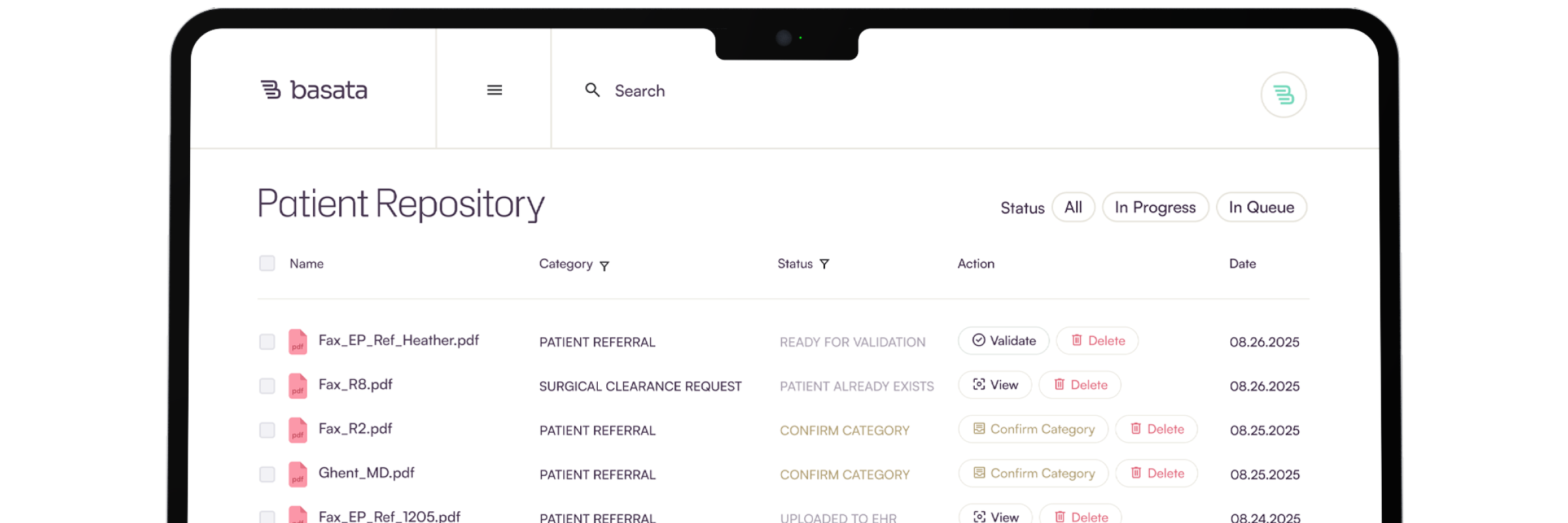
Knowledge Drops
Jun 2, 2025
Making AI Actually Useful: How LLMs Get Put to Work

Now that you understand what LLMs are and their limitations, let's tackle the practical question that matters most: how do you actually harness this powerful technology to perform useful tasks?
When vendors talk about "AI solutions," they're often using different techniques to make LLMs do specific work. Understanding these core approaches will help you cut through the marketing jargon and evaluate what's actually happening behind the scenes. Here are the main techniques that developers and companies use to transform raw LLM capabilities into practical applications:
Prompt Engineering: The Art of AI Communication
Think of prompt engineering as learning to speak "AI language." Just as you might phrase requests differently when speaking to different staff members based on their expertise, how you "ask" an AI system to perform a task dramatically affects the results.
Behind the scenes, vendors are:
- Creating prompts with clear instructions, relevant context, and examples of desired outputs
- Using well-crafted prompts to reduce hallucinations by constraining the AI to specific domains or formats
- Continuously testing and refining these prompts to turn vague, error-prone outputs into reliable, consistent results
For example, a vendor's document processing system isn't just "asking" the AI to summarize content. They've likely spent months refining instructions like: "Create a concise summary of this patient encounter note, focusing on diagnosis, treatment plan, and follow-up instructions. Format the summary with clear headings for each section." These precise instructions, invisible to the end user, are what make the difference between an unreliable demo and a production-ready solution.
RAG (Retrieval-Augmented Generation): Grounding AI in Facts
RAG is a powerful approach that addresses one of LLMs' biggest weaknesses: their tendency to hallucinate when they don't know something. Here's how it works:
- Your practice connects the LLM to authoritative information sources (like your EMR, practice guidelines, or billing systems)
- When asked a question, the system first retrieves relevant information from these trusted sources
- The LLM then generates responses based on this verified information
The key insight with RAG is that it's essentially an extension of prompt engineering—the system is automatically injecting relevant facts into the prompt and instructing the LLM to "answer based only on the information provided." This creates a powerful combination: the LLM's language capabilities with the accuracy of verified information.
Behind the scenes, RAG systems work through a process called "vectorization"—converting your documents into a special mathematical format (think of it as creating a digital "fingerprint" of each piece of information). When someone asks a question, the system converts that question into the same mathematical format and finds the most similar "fingerprints" in your knowledge base, pulling that information into the prompt.
This is particularly valuable in healthcare, where accuracy matters. A RAG-powered system answering questions about insurance coverage would first retrieve the actual policy details before generating an explanation, dramatically reducing hallucination risks.
AI Agents: Orchestrating Complex Workflows
For more sophisticated use cases, AI agents can coordinate multi-step processes by breaking complex tasks into manageable pieces:
- Agents use LLMs to plan a sequence of actions to achieve a goal
- They can interact with multiple systems (EMR, scheduling, billing) to complete tasks
- They include reasoning capabilities to handle exceptions and make appropriate decisions
- Systems can deploy multiple agents that verify each other's work, dramatically reducing hallucination risks
This multi-agent approach is one of the most powerful ways to reduce errors. For example, one agent might generate content while another specialized "critic" agent reviews that content for accuracy against trusted sources. This creates a system of checks and balances that significantly improves reliability.
For example, an AI agent processing a new patient referral might extract information from the referral document, check insurance eligibility, identify appropriate providers based on specialties needed, find available appointments, and draft the initial communication—all as a coordinated workflow rather than isolated tasks. A verification agent could then double-check that the extracted information matches the original referral document before the workflow proceeds.
Fine-Tuning: Understanding Vendor Approaches and Risks
While prompt engineering, RAG, and AI agents can work effectively with general-purpose LLMs, some vendors offer "fine-tuned" models—custom versions specifically trained on healthcare or other domain-specific data. But what does this really mean, and what are the tradeoffs?
When a vendor mentions their "fine-tuned model," they're typically referring to additional training they've conducted on a specific dataset to adapt a general-purpose LLM to a particular domain or task. This process involves exposing the model to thousands of examples to adjust its internal parameters. Here's what you should understand about fine-tuning:
- Potential benefits: Fine-tuned models can sometimes provide better domain-specific performance and efficiency for certain specialized tasks
- Data requirements: Vendors need substantial amounts of high-quality data (often thousands of examples) to create effective fine-tuned models
- Compliance considerations: Be wary of how vendors handle healthcare data during fine-tuning, as this raises serious HIPAA and other regulatory concerns
However, recent research reveals significant downsides to fine-tuning that many vendors won't mention:
- Safety and alignment concerns: Fine-tuning, even with benign datasets, can actually break a model's safety guardrails and alignment, making it more prone to errors or inappropriate outputs
- Diminished capabilities: Fine-tuning for one capability can sometimes reduce the model's performance in other areas, a phenomenon known as "catastrophic forgetting"
- Ongoing maintenance needs: Fine-tuned models require continuous updating as healthcare practices and regulations evolve
When evaluating vendor solutions, it's important to understand their approach to model development. Some vendors heavily market their "fine-tuned" models as a competitive advantage, while others focus on sophisticated prompting and RAG techniques with general-purpose models. Neither approach is inherently superior—what matters is the actual performance and reliability of the solution with your specific use cases and data. A well-designed system using prompt engineering and RAG often delivers better results than a poorly fine-tuned model, and at significantly lower risk. When vendors emphasize their "custom fine-tuned models," ask critical questions about how they maintain safety, prevent capability degradation, and handle ongoing updates.
The Critical Importance of Testing and Evaluation
When considering AI solutions for your practice, remember this golden rule: Never implement an AI system without thoroughly testing it on your own data first. Here's why this matters:
- Hallucination risks vary dramatically across different contexts and data types
- What works perfectly in one medical practice might fail in yours due to differences in documentation styles, patient populations, or workflow processes
- Every AI model has different "blind spots" that only reveal themselves during real-world testing
Be extremely skeptical of any vendor that resists testing their AI solution with your actual data before full implementation. A reputable AI partner will insist on running pilots to demonstrate performance and identify potential issues before full deployment.
Mitigating Hallucination Risks
The good news is that hallucinations can be managed through thoughtful implementation strategies. The appropriate approach depends on your risk assessment:
For high-risk contexts (where incorrect information could impact patient care or compliance):
- Implement human review of all AI-generated content before it's used
- Create systems that verify AI outputs against authoritative sources
- Use AI as a first draft generator rather than a final authority
For medium-risk contexts (where errors would cause inefficiency but not harm):
- Implement spot-checking protocols where humans verify a percentage of AI outputs
- Design workflows where AI and humans collaborate, with clear escalation paths
- Provide clear feedback mechanisms to improve the system over time
For low-risk contexts (where occasional errors are tolerable):
- Use AI more autonomously, but with clear monitoring for unusual patterns
- Design user interfaces that make it easy to identify and correct AI errors
- Build in automated checks for common issue types
The right approach depends on your specific needs, but the key principle remains: AI implementations should be matched with appropriate oversight mechanisms based on a realistic assessment of both the benefits and risks.
Curious about Basata? Learn how you can give your admin team superpowers.
See related articles








Ready for your administrative breakthrough?
Get in touch today and learn how Basata can give your admin team superpowers.